The Deep Research Analyst System Design
Architecting Recursive Agent Loops for "McKinsey-Grade" Market Intelligence
Author: AgileWoW Team
Category: Financial Intelligence / Recursive Architecture
Read Time: 12 Minutes
Parent Guide: The Agentic AI Engineering Handbook
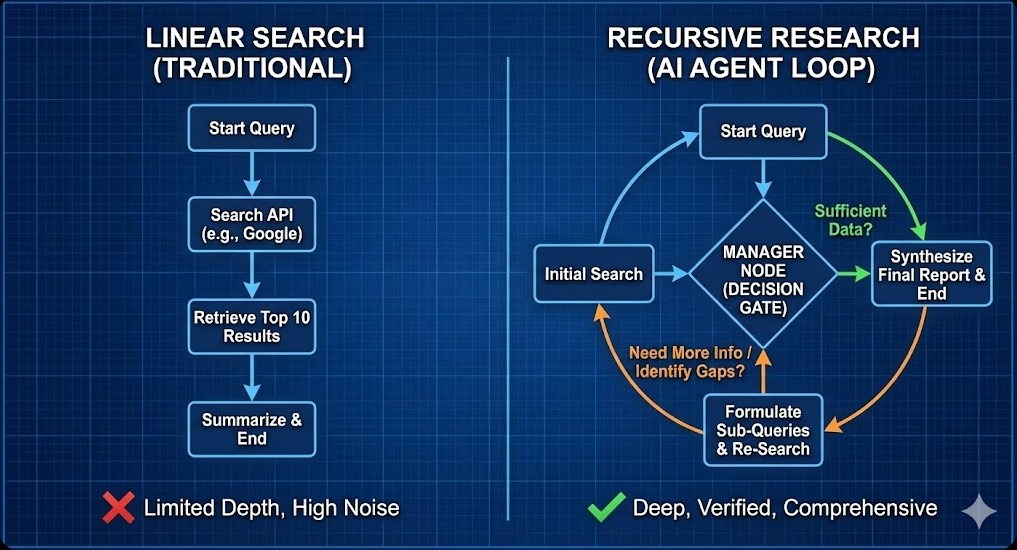
In 2024, "research agents" were mostly wrappers around Google Search API. They would fetch 10 links, summarize them, and stop. They lacked depth.
The Deep Research Analyst is a Tier 2 agentic system designed to mimic a human strategy consultant. It doesn't just "search"; it investigates. It formulates a hypothesis, gathers evidence, identifies gaps in that evidence, and recursively searches again until it has a defensible answer.
The engineering challenge here is not finding data—it is stopping. Without architectural guardrails, recursive agents fall into "Rabbit Holes," endlessly clicking links until they burn through your token budget. This blueprint details the Cyclic Graph Architecture required to build a disciplined, self-correcting research engine.
1. The Design Challenge: The "Rabbit Hole" Problem
A junior human analyst knows that if they can't find a specific revenue figure after 30 minutes, they should estimate it or look for a proxy. An AI agent does not.
The Failure Mode:
Goal: "Find the 2025 revenue projection for Acme Corp."
Agent: Searches Google. Finds nothing.
Agent: Clicks "Page 2" of results. Finds nothing.
Agent: Reformulates query to "Acme Corp financial report." Finds nothing.
Result: Infinite loop of wasted compute.
The Architectural Goal: Implement "Metacognition" (Thinking about Thinking). The system needs a "Manager Node" that evaluates the quality of search results and decides whether to pivot, dig deeper, or give up and synthesize.
2. The Tech Stack Selection
To build a researcher that rivals a top-tier consultant, we need a stack that handles long-context retrieval and hallucination checks.
| Component | Choice | Why? |
|---|---|---|
| Orchestrator | LangGraph | We need a State Machine (not a Chain) to handle the cyclic "Research -> Critique -> Research" loop. |
| Search Tool | Tavily / Exa | Unlike Google, these APIs return "LLM-ready" clean text, optimized for extracting facts, not just links. |
| Validation | DeepEval / G-Eval | Automated unit tests to check if the generated citations actually exist in the source text. |
| Framework | SCQR & Minto Pyramid | The structural framework used to force the LLM to write like a strategy consultant. |
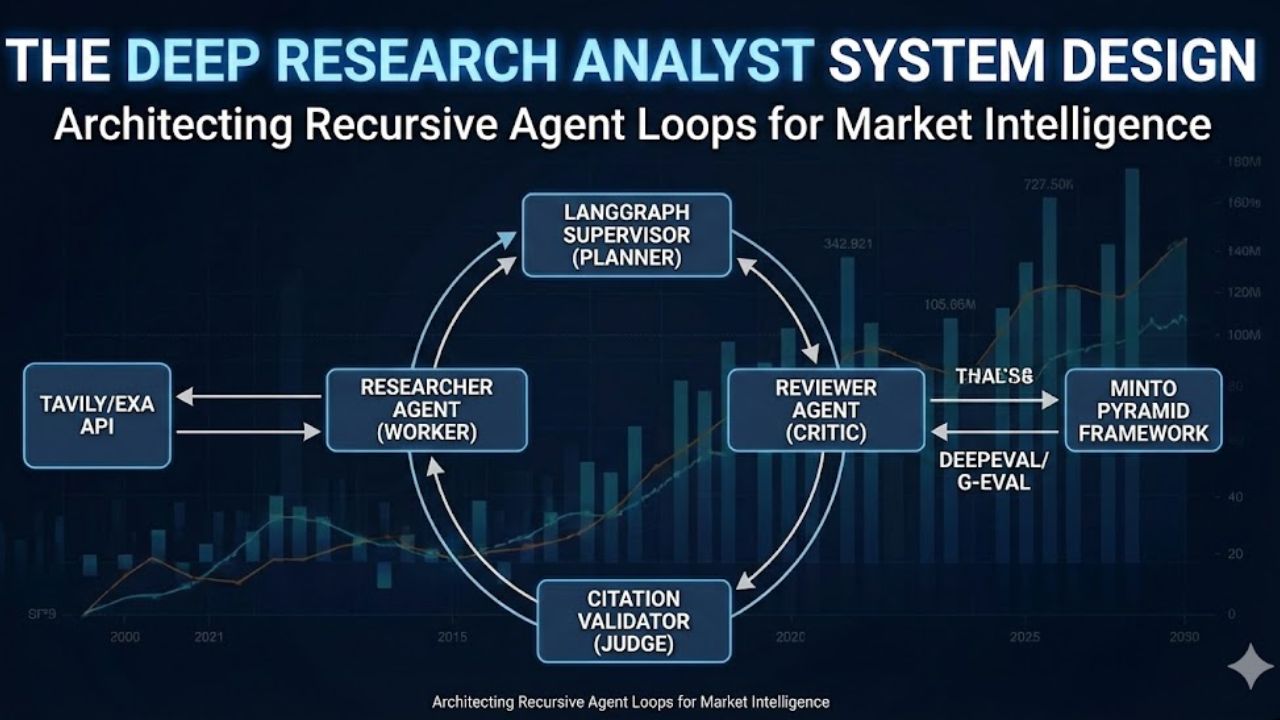
3. Architecture Deep Dive: The Recursive Loop
3.1 The "Plan-and-Solve" Pattern
Instead of asking the LLM to "Research AI trends," we break the process into three distinct Agent Roles managed by a Supervisor.
- The Planner (Supervisor):
- Input: "Should we invest in NVIDIA?"
- Action: Decomposes the query into sub-questions: "1. What is NVIDIA's current P/E ratio? 2. What are the supply chain risks for H100 chips? 3. Who are the emerging competitors in custom ASICs?"
- The Researcher (Worker):
- Action: Takes one sub-question, executes 3-5 search queries, reads the content, and summarizes findings into "Evidence Chunks."
- The Reviewer (Critic):
- Action: Reads the Evidence Chunks. Asks: "Is this sufficient to answer the user's core question?"
- Decision: If YES -> Pass to Writer. If NO -> Send specific feedback back to Planner.
3.2 The Citation Validation Layer
Trust is binary. One fake number ruins the report. We implement a "Citation Check" node before the final output.
- Logic: For every sentence with a citation [1], the Agent must extract the sentence and the source URL content.
- Verification: A cheaper model (e.g., GPT-4o-mini) acts as a Judge: "Does the text in Source [1] support the claim made in Sentence A?"
- Outcome: If the check fails, the sentence is removed or flagged as "Unverified."
4. Prompt Engineering: The "McKinsey" Style
To get a report that looks professional, we use the Minto Pyramid Principle in our system prompt.
"You are a Senior Partner at a top-tier strategy consulting firm.
Structure: Use the Minto Pyramid Principle. Start with the Key Recommendation (The 'Answer') first. Follow with 3 supporting arguments.
Format: Use the SCQR framework (Situation, Complication, Question, Resolution) for the Executive Summary.
Tone: Assertive, data-driven, and crisp. No fluff. No 'I hope this helps.'
Constraint: Every claim must have a citation [x] from the provided context."
5. Implementation Guide (LangGraph)
Phase 1: Define the State
We use a TypedDict to track the research progress.
class ResearchState(TypedDict):
question: str
sub_questions: List[str]
evidence: List[Document]
iteration_count: int # CRITICAL: Prevents infinite loops
max_iterations: intPhase 2: The "Rabbit Hole" Circuit Breaker
Inside your graph definition, add a conditional edge:
def should_continue(state):
if state['iteration_count'] >= state['max_iterations']:
return "finalize" # Force stop if we hit the limit
if review_node(state) == "sufficient":
return "finalize"
return "research_more"Why this matters: This simple integer check (iteration_count) is the difference between a $2.00 API bill and a $200.00 API bill.
Phase 3: The "Deep Search" Tool
Don't just search once. Use a "Fan-Out" strategy.
- Query: "AI Agent Market Size"
- Fan-Out: The agent generates 3 variations: "Generative AI Market CAGR," "Agentic AI adoption rates 2025," "Enterprise AI spending trends."
- Execution: Run these 3 searches in parallel (using
asyncio) to speed up the "Thinking" time.
6. Use Cases for Financial Intelligence
1. Venture Capital Due Diligence:
Input: A pitch deck PDF + Competitor Names.
Output: A 10-page "Red Flag Report" analyzing the startup's claims against real market data.
2. Supply Chain Risk Monitoring:
Input: "Analyze lithium shortage risks for 2026."
Output: A strategic memo detailing geopolitical risks in specific mining regions, verified by recent news.
3. Competitor Product Feature Matrix:
Input: "Compare CrewAI vs. LangGraph pricing and enterprise features."
Output: A side-by-side table with citations pointing to the official documentation pages.
7. Frequently Asked Questions (FAQ)
A: Use "Time-Boxing" and "Iteration Limits." In LangGraph, set a strict max_iterations=5 in your state schema. Also, instruct the Planner Agent to "Broaden" the search if specific data points (like private revenue figures) are not found after 2 attempts.
A: Yes. This is where MCP (Model Context Protocol) comes in. You can connect a "PDF Reader" tool via MCP. The agent can then "read" a local 10K report and combine that internal data with external web search results for a hybrid analysis.
A: Absolutely. The "McKinsey" style (Pyramid Principle) is just a gold standard for clarity. You can swap the System Prompt to be "Academic Researcher" (focusing on methodology and citations) or "Tech Blogger" (casual, opinionated) depending on your audience.
A: For AI agents, yes. Google returns HTML soup with ads and navbars. Tavily/Exa returns cleaned, parsed text chunks that fit perfectly into an LLM's context window, reducing token costs and hallucination risks.

8. Sources & References
Open Source Resources:
Architecture & Frameworks
- LangGraph: Deep Research Agent Tutorial – Official guide on building cyclic research loops.
- Tavily API: Search for AI Agents – The search engine optimized for LLMs.
Methodology
- The Minto Pyramid Principle: McKinsey Alumni Center – The standard for structuring strategic communication.
- Reflexion Paper: Reflexion: Language Agents with Verbal Reinforcement Learning – The academic basis for the "Reviewer/Critic" node.
Tools
- DeepEval: Hallucination Metrics – Framework for unit testing your agent's citations.