Trace a 12-Step Multi-Agent Run: 5 Spans You Must Capture
Key Takeaways
- The Handoff Blind Spot: Failing to capture planner-to-worker handoffs is the number one cause of broken production traces.
- Trace Context Propagation: You must inject unique run IDs across all parallel sub-agents to stitch workflows together.
- Loop Control Strategies: Without proper span bounding, looping agents will cause trace explosion and bankrupt your observability budget.
- The MCP Connection: Tracing external agent-to-agent calls via the Model Context Protocol (MCP) requires specialized boundary spans.
How to instrument multi-agent workflow tracing: the 5 spans 80% of teams forget, including planner-to-worker handoffs.
You ship your orchestrator to production, but when a complex task fails at step 9, your logging dashboard is a completely unreadable mess of disconnected LLM calls.
If you have already implemented our comprehensive AI agent observability playbook, you know that traditional single-turn tracing is dead.
You cannot simply log prompt inputs and outputs anymore. To successfully monitor distributed, autonomous systems, you must capture the exact micro-interactions between your agents.
This deep dive reveals the precise span architecture required to track cross-agent state, isolate routing errors, and prove your system's ROI.
The Multi-Agent Observability Blind Spot
When you move from simple chains to a supervisor-worker pattern, traditional Application Performance Monitoring (APM) breaks down.
An orchestrator might spawn three parallel workers, each triggering their own tools asynchronously.
If these asynchronous loops are not bound by a parent trace, they appear as isolated, anomalous API calls.
When you are figuring out exactly how to debug LangGraph agent silent tool failure, you will quickly realize that missing context propagation is usually the culprit.
Why Default Wrappers Fail
Auto-instrumentation tools are great for basic LangChain scripts, but they fail spectacularly in multi-agent environments.
They typically wrap the highest-level execution and drop the trace context the moment a sub-agent spins up a new thread.
To achieve true distributed agent tracing, you must manually define the boundaries of your agentic workflows using specific, targeted span schemas.
The 5 Critical Spans You Must Capture
If you want to maintain visibility and calculate accurate task success rates per agent role, you must instrument the following five spans within your code.
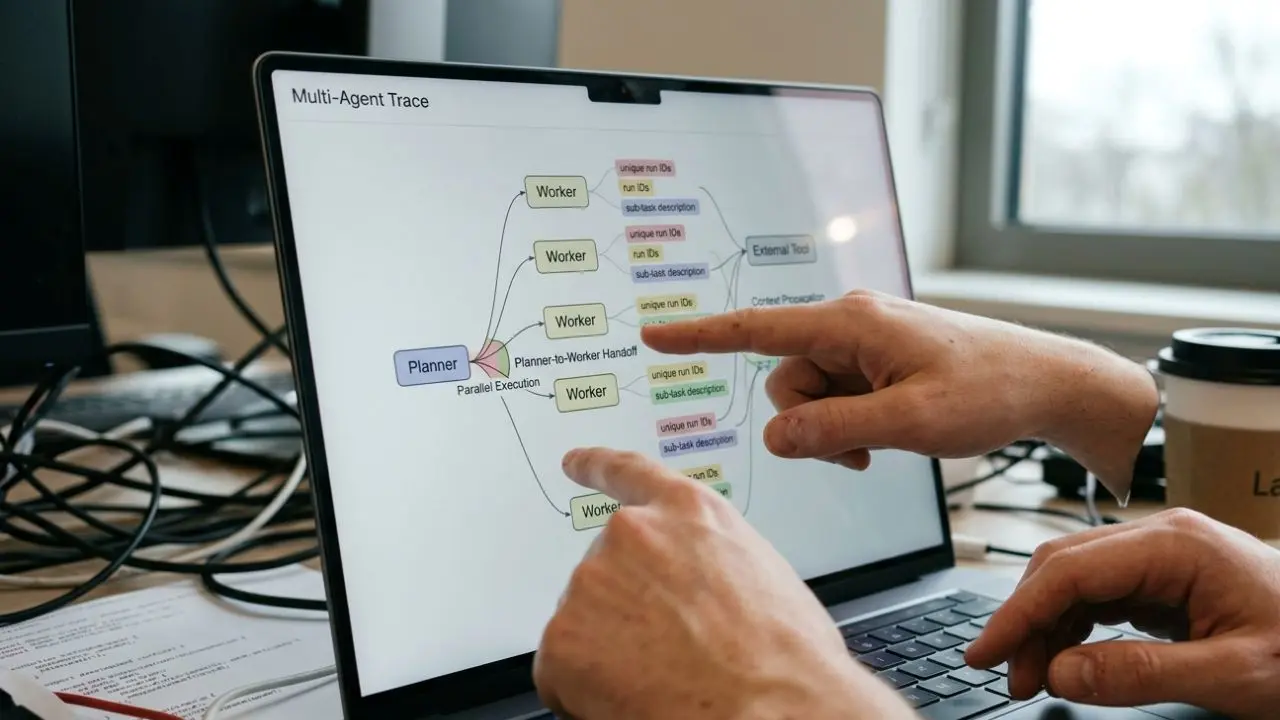
1. The Planner-to-Worker Handoff Span
The most critical point of failure occurs when a supervisor agent delegates a task.
You must create a dedicated Handoff Span that logs the exact instructions passed to the worker.
This span should include the generated sub-task description and the specific tools the worker is authorized to use.
If the worker fails, this span proves whether the failure was due to bad instructions or bad execution.
2. The Cross-Agent Context Propagation Span
How do you propagate trace context between two agent services?
You achieve this by capturing a Context Propagation Span.
Before a worker thread initiates, you must extract the OpenTelemetry trace_id and span_id from the parent process.
Inject these IDs into the payload sent to the worker, ensuring the child service attaches all subsequent LLM calls to the original trace tree.
3. The Parallel Execution Span
When tracing parallel sub-agents, you must wrap the entire asynchronous scatter-gather process in a Parallel Execution Span.
This allows you to visualize exactly which worker agent is the bottleneck.
It clearly maps out the timeline, showing if Worker A took 2 seconds while Worker B timed out after 45 seconds.
4. The External Tool & MCP Execution Span
When tracing an agent that calls another agent through MCP, standard tool tracing is insufficient.
You must define an MCP Boundary Span that logs the initial request protocol, the exact payload sent across the Model Context Protocol, and the latency of the external agent's response.
This is vital for vendor SLA monitoring.
5. The Synthesizer & Output Verification Span
Finally, the orchestrator must synthesize the responses from all workers.
The Synthesis Span captures the final LLM call that merges the parallel outputs.
This span must log the raw inputs from all workers alongside the final response presented to the user, proving that no critical data was dropped during the final consolidation.
Managing Trace Explosion and Sampling
Capturing these spans generates massive data. If you have a LangGraph setup where an agent loops 30 times, logging every single token will destroy your budget.
You must implement an intelligent sampling strategy for production multi-agent runs.
If you want to know what to do after you ship: agent observability, start by configuring your collector to sample 100% of failed multi-agent traces, but only 5% of successful, repeating loops.
Frequently Asked Questions (FAQ)
How do I trace a multi-agent workflow end to end in 2026?
You must move beyond simple LLM auto-instrumentation. Utilize explicit trace context propagation to link parent orchestrators with child workers, ensuring every API call, tool execution, and asynchronous thread is bound to a single, unified transaction ID.
What spans should I capture for a planner-worker agent pattern?
At a minimum, capture the initial user request, the planner's routing decision, the explicit handoff payload sent to the worker, the worker's internal tool executions, and the final synthesis span where the planner merges the worker outputs.
How do I propagate trace context between two agent services?
Extract the active trace context (Trace ID and Span ID) from your parent service using standard OpenTelemetry libraries. Inject these identifiers into the HTTP headers or message queue payload sent to the secondary agent service to stitch the distributed trace.
How do I visualize agent handoffs in LangSmith or Langfuse?
Properly configured spans will automatically generate hierarchical trace trees. In LangSmith or Langfuse, use custom run IDs and tags specific to the worker's name. This allows the dashboard UI to clearly nest the handoff logic under the supervisor's primary execution.
What is the correct way to trace parallel sub-agents?
Wrap the asynchronous asyncio.gather or thread pool execution in a parent span. Ensure each parallel worker initializes its own distinct child span linked to that parent. This guarantees the tracing UI accurately renders the overlapping timelines side-by-side.
How do I avoid trace explosion when an agent loops 30 times?
Implement tail-based sampling or conditional span dropping. Configure your observability SDK to aggregate repetitive, successful loops into a single summary span, while maintaining high-fidelity, token-by-token logging strictly for loops that throw exceptions or return error states.
Can I use OpenTelemetry context for cross-agent trace propagation?
Absolutely. OpenTelemetry context propagation is the industry standard for this exact scenario. It natively supports injecting and extracting W3C Trace Context headers, ensuring seamless visibility across different agent frameworks, microservices, and external vendor APIs.
How do I add business metrics like task success rate per agent role?
You must attach custom metadata or attributes to your terminal spans. Append tags like agent_role: researcher and task_status: success. You can then query these specific span attributes in your APM backend to build role-specific performance dashboards.
How do I trace an agent that calls another agent through MCP?
Treat the Model Context Protocol (MCP) call identically to a distributed microservice call. Create a boundary span right before the MCP request fires off, injecting your active trace ID into the protocol headers so the receiving agent can continue the trace.
What is the right sampling strategy for production multi-agent runs?
Do not use flat head-based sampling. Implement dynamic tail-based sampling at the collector level. Retain 100% of traces containing errors, rollbacks, or high-latency spikes, but aggressively sample down (e.g., to 5%) the structurally repetitive, successful 200 OK runs.