Cost of Running LLM Locally vs Cloud: The 2026 ROI Analysis for CFOs
Quick Answer: The 2026 Financial Verdict
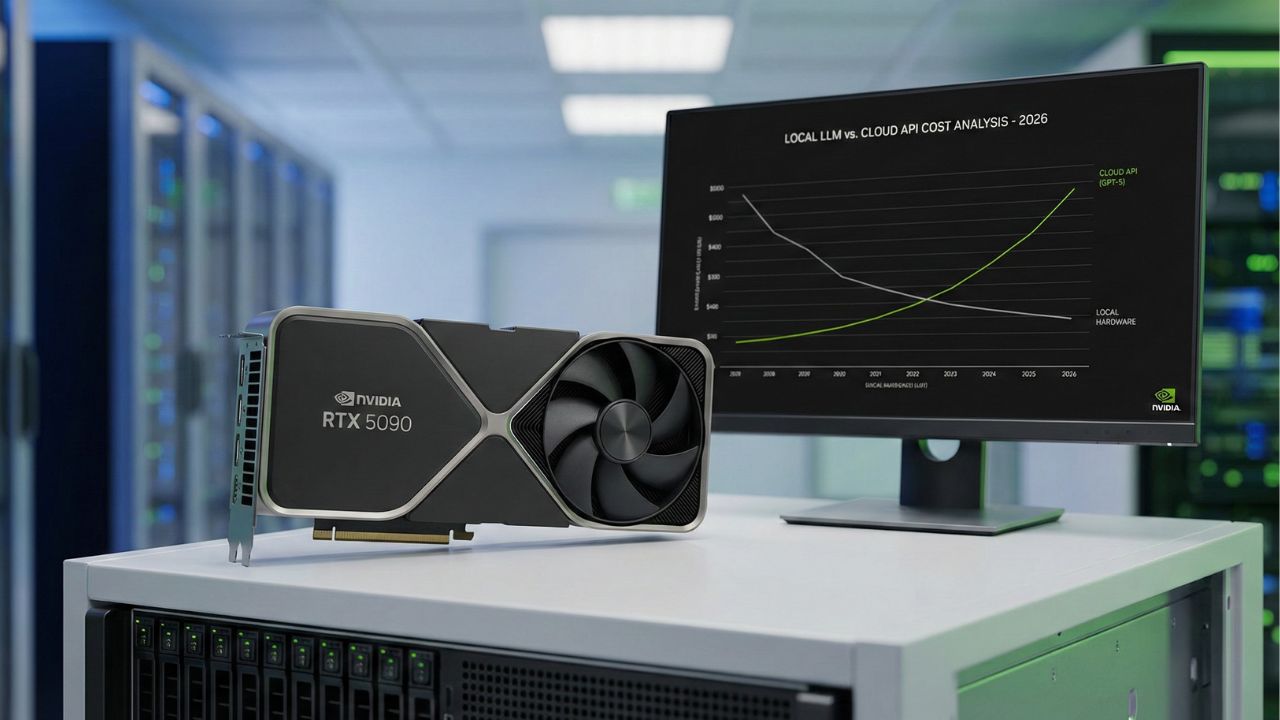
- The Breakeven Point: For high-volume teams, a $3,000 NVIDIA RTX 5090 pays for itself in just 4 months compared to enterprise GPT-5 API costs.
- The Privacy Premium: Local hosting eliminates data egress fees and compliance risks, a "hidden value" often worth 20% of the total TCO.
- OpEx vs. CapEx: Shifting from unpredictable monthly API bills (OpEx) to one-time hardware purchases (CapEx) stabilizes cash flow for startups.
- Token Economics: Once hardware is purchased, the marginal cost per token drops effectively to zero (excluding electricity).
The CFO's Dilemma: Rent or Buy Intelligence?
In 2026, the cost of running LLM locally vs cloud is no longer just a technical decision, it is a balance sheet decision.
For years, the "Cloud First" mantra made sense. Why buy servers when you can rent?
But with the release of heavyweights like Gemini 3 Pro and the massive token consumption of autonomous agents, cloud API bills are spiraling out of control.
This deep dive is part of our extensive guide on Live Leaderboard 2026: Gemini 3 Pro vs. DeepSeek vs. GPT-5.
While those frontier models define the ceiling of intelligence, local hardware defines the floor of profitability.
Here is the ROI analysis every CFO needs to see before signing another cloud contract.
1. The Token Math: When to Switch
The math is simple, but the results are shocking.
Cloud providers charge per million tokens. This sounds cheap until you realize an autonomous coding agent might read a codebase 500 times a day.
The 2026 Cost Curve:
- Low Volume: If you use < 100M tokens/month, Cloud is cheaper.
- Medium Volume: At 500M tokens/month, you enter the "Danger Zone" where costs equalize.
- High Volume: Above 1B tokens/month, Local is exponentially cheaper.
2. Hardware: The RTX 5090 & Mac M5 Max
The hardware landscape has shifted dramatically this year.
Consumer-grade GPUs now possess the VRAM capabilities that used to belong exclusively to enterprise H100 clusters.
The Contenders:
- NVIDIA RTX 5090 (2026): The powerhouse. Capable of running quantized 70B models at blazing speeds.
- Apple M5 Max: Unified memory architecture allows massive context windows, perfect for RAG applications on a laptop.
Buying an AI Workstation is a one-time depreciation event. Renting GPT-5 is a forever tax on your revenue.
3. The Hidden "Cloud Tax"
The sticker price of an API token is not the true cost.
When you rely on the cloud, you pay hidden fees that destroy margins.
Hidden Costs Include:
- Data Egress Fees: Paying to move your own data out of the cloud.
- Latency Penalties: Waiting for an API response kills developer flow. Local inference is often instant.
- Privacy Compliance: Redacting PII before sending data to OpenAI requires expensive middleware.
More importantly, shifting to local infrastructure is a key driver in reducing marketing stack consolidation costs.
4. Electricity: The Only Recurring Cost
Skeptics argue that electricity eats up the savings.
In 2026, this argument is largely debunked for inference tasks.
The Reality:
- Running a local 70B model requires roughly 300-400 Watts during active generation.
- Even at high industrial electricity rates, the cost to generate 1M tokens locally is pennies.
- Compare this to the $5.00 - $15.00 per 1M tokens charged by frontier model APIs.
The electricity cost is a rounding error compared to the markup Big Tech charges for their compute.
Conclusion
The cost of running LLM locally vs cloud ultimately comes down to your scale.
For hobbyists and sporadic users, the cloud remains convenient.
But for AI-native companies where token generation is a core business activity, renting intelligence is financial suicide.
Investing in local hardware like the RTX 5090 or Mac M5 Max isn't just about speed, it's about owning your infrastructure and capping your downside risk.
Compare Market Intelligence Tools. Try SimilarWeb

We may earn a commission if you buy through this link. (This does not increase the price for you)
Frequently Asked Questions (FAQ)
Enterprises switching from GPT-4o heavy usage to local Llama 3 models often report savings of 60-80% in the first year, even after factoring in hardware costs.
If your team generates more than 500M tokens per month, buying the RTX 5090 is cheaper. The card typically pays for itself within 3-5 months of heavy usage.
For a standard workstation running 8 hours a day, electricity costs are typically under $15-$20 per month, significantly less than a single day of heavy API usage.
Yes. By capping compute costs at the price of hardware, startups avoid the "success disaster" where a viral product leads to bankruptcy-inducing API bills.
For developers needing mobility, yes. Its unified memory allows running larger models than most consumer PC GPUs, essentially acting as a portable server.