RAG Evals in Prod: 5 Metrics CTOs Demand in 2026
- LLM-as-a-Judge scales observability: Sampling 5% of production traffic through smaller, specialized models replaces expensive human labeling.
- Isolate the failure domains: You must mathematically separate retrieval failures (bad context) from generation failures (hallucinations).
- The CFO Metric: Engineering metrics mean nothing if you cannot track the specific infrastructure cost per successful RAG query.
- Golden sets decay: Static 500-question eval datasets rot over time; continuous synthetic data generation is now required for CI/CD pipelines.
Your RAG pipeline passed the vibe check in development. But pushing it to production without continuous monitoring? That is exactly how a silent 30% hallucination rate triggers a massive CFO escalation.
Most engineering teams ship three basic metrics and completely miss the critical indicators that actually predict enterprise user satisfaction. As we detailed in our comprehensive guide on the production-rag-cost-architecture, unmonitored architectures quickly spiral into six-figure financial disasters.
Relying on manual spot-checks is no longer a viable engineering strategy. In 2026, implementing robust rag evaluation metrics production monitoring is a mandatory prerequisite for enterprise deployment. Here is the highly technical, five-metric scorecard that top-tier teams use to maintain strict SLA compliance.
The Production Reality of RAG Evaluation Metrics
Transitioning from a Jupyter notebook to a production environment requires a mindset shift. In dev, you optimize for accuracy. In production, you optimize for the Cost-per-Successful-Answer.
Why the 'Vibe Check' Fails at Enterprise Scale
In the pilot phase, it’s tempting to look at ten answers and say, "Looks good." But when you scale to 500,000 documents and 10,000 queries per day, manual review is impossible. You need an automated grading system that operates with the same rigour as your unit tests.
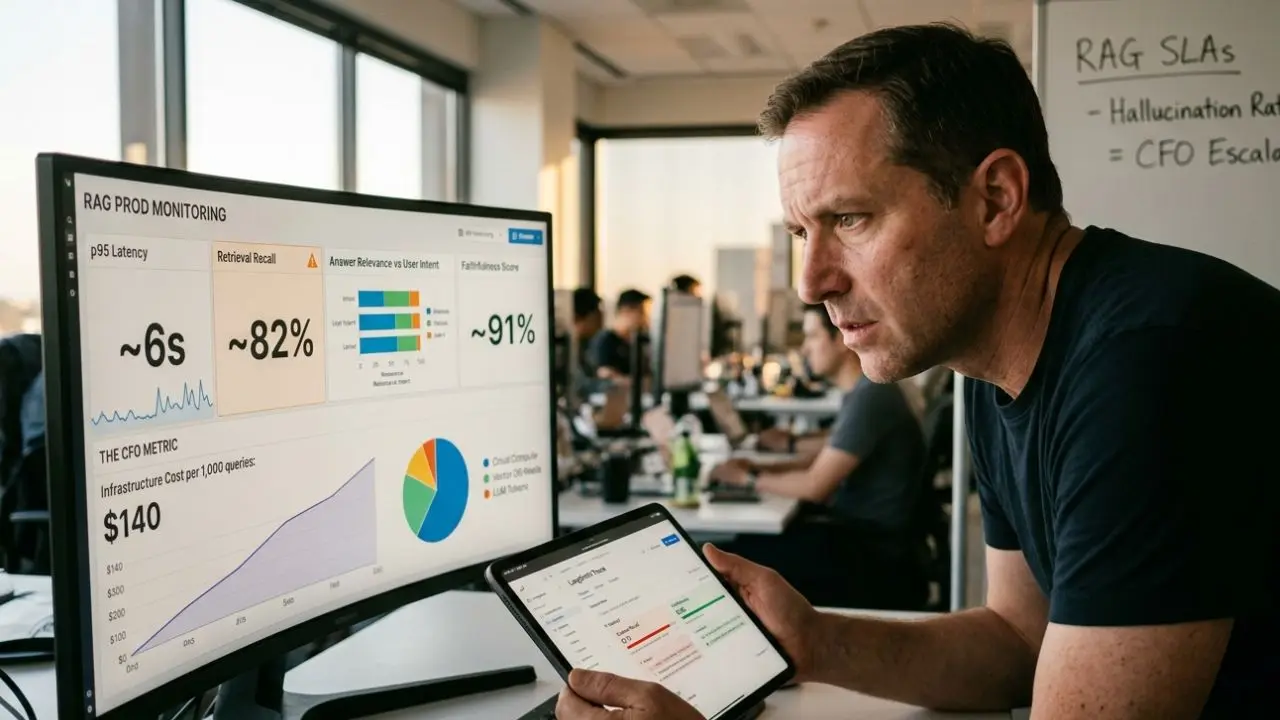
The 5-Metric Scorecard for 2026 SLAs
A production-ready RAG system must be evaluated on these five dimensions to ensure it remains both accurate and financially viable.
Metric 1: Retrieval Recall (The Context Floor)
This evaluates your vector database cost effectiveness. If the answer is in your corpus but your search returns irrelevant chunks, the LLM will fail by default. Recall measures the percentage of queries where the "ground truth" information was present in the retrieved context.
Metric 2: Generation Faithfulness (Grounding)
Also known as "Groundedness," this metric identifies hallucinations. It asks: "Is every claim in the answer supported by the retrieved chunks?" If the LLM uses its pre-training data to answer instead of the provided documents, it is unfaithful and dangerous for compliance-heavy use cases.
Metric 3: Answer Relevance (User Intent)
An answer can be factually correct but completely irrelevant to the user’s intent. This metric evaluates how well the generated response actually addresses the specific question asked. High relevance is the primary driver of user retention in agentic rag vs naive rag architecture benchmarks.
Metric 4: Latency at p95 (The Patience Threshold)
Average latency is a lie. You must track the p95—the experience of the unluckiest 5% of your users. If you haven't learned how to reduce rag latency, your p95 will often exceed 5 seconds, leading to abandonment and re-querying, which doubles your token burn.
Metric 5: Infrastructure Cost per 1,000 Queries
The "CFO Metric." You must roll up vector DB fees, embedding refreshes, and LLM context window costs into a single business-relevant figure. If this number trends upward while user satisfaction stays flat, your architecture is bleeding money.
Implementing LLM-as-a-Judge in CI/CD
In 2026, specialized small models (like a fine-tuned Llama 3 8B) are used as "judges" to grade production traffic. By sampling 5% of live queries and passing them to a judge model, you get a real-time accuracy dashboard without the $50/hour cost of human evaluators.
Streamline Your Business Communications with AI. Try Cloud Talk

We may earn a commission if you buy through this link. (This does not increase the price for you)
Frequently Asked Questions
What is the industry standard for RAG observability?
In 2026, LangSmith has emerged as the definitive platform for enterprise RAG observability. It seamlessly captures inputs, outputs, and intermediate retrieval steps, making it the industry standard for LangChain observability.
How do you separate retrieval failures from generation failures in metrics?
You measure them independently using distinct metrics. Context Relevancy and Context Recall specifically evaluate the retrieval engine's accuracy. Faithfulness and Answer Relevance evaluate the LLM's ability to synthesize that retrieved information.
What dashboards do enterprise RAG teams show their CTO weekly?
They present a unified 5-metric scorecard: Retrieval Recall, Generation Faithfulness, Answer Relevance, p95 Latency, and the Total Infrastructure Cost per 1,000 queries. This perfectly balances quality, speed, and financial viability.
Does golden-set evaluation scale beyond a 500-question dataset?
Static datasets rapidly decay. To scale beyond 500 questions, teams must implement synthetic data generation pipelines that continuously extract complex, edge-case queries from actual production logs to automatically update their evaluation sets.