Best AI for Text to Video (April 2026): The LMSYS Video Arena Leaders

Data Verified: April 2, 2026
Quick Answer: Key Takeaways
- The Data Speaks: Our rankings are drawn exclusively from the LMSYS Video Arena's crowdsourced Elo ratings.
- Temporal consistency solved: Leading models no longer suffer from randomly morphing subjects between frames.
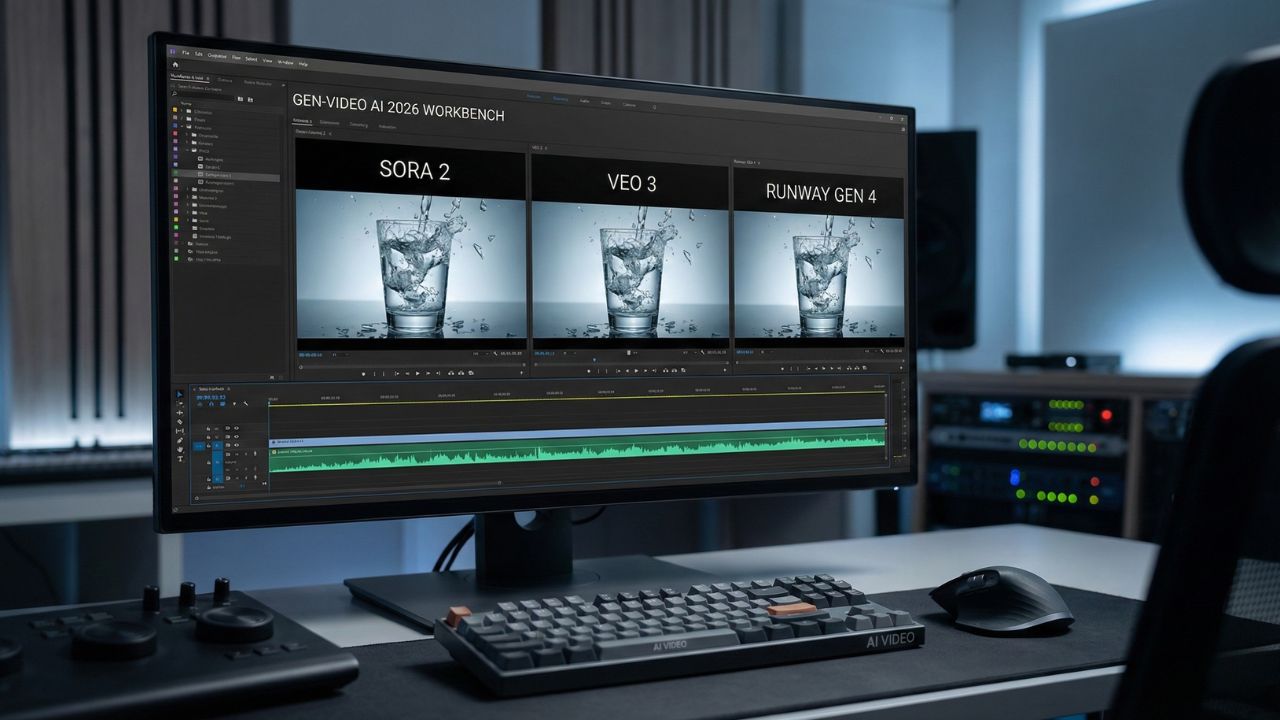
- Flawless physics simulation: Water, gravity, and object collisions behave according to real-world physical laws.
- Native audio generation: Top-tier models now generate perfectly synced Foley and ambient sound directly within the video file.
Are you an AI novice or a 2026 expert? Test your knowledge with our 15-question professional certification prep. Estimated time: 5 minutes.
Start the AssessmentIf you want to view the best AI for text to video in April 2026, you cannot rely on carefully curated marketing reels. You must compare the heavyweight generators based entirely on blind, human-preference testing.
This deep dive is part of our extensive guide on Best AI Models 2026. Early generative video was notorious for melting backgrounds and bizarre gravity, but today's engines have officially passed the "physics test," turning simple text into Hollywood-grade footage.
How We Ranked the Video Generators (LMSYS Data Only)
To establish the true hierarchy of video generation in 2026, we rely strictly on the LMArena (LMSYS) Video Leaderboard. This platform forces users to input a prompt, generates two anonymous videos side-by-side from different models, and asks the human to vote on the winner based on prompt adherence, temporal consistency, and visual quality. The resulting Elo rating is the most accurate reflection of actual model capabilities available today.
| # | Video AI Model | Key Strength (LMSYS Arena) | Pricing |
|---|---|---|---|
| 1 | Sora 2 (OpenAI) | Highest overall Elo; unmatched 3D physics and object permanence | ChatGPT Pro |
| 2 | Google Veo 3.1 | Top Elo for prompt adherence and synchronized native audio | Free / Paid API |
| 3 | Hailuo AI (MiniMax) | Massive upset winner in blind tests for photorealism and fluid dynamics | Free / Paid |
| 4 | Kling V3 (Kuaishou) | Consistently dominates in cinematic aesthetics and human expressions | Paid Subscription |
| 5 | Runway Gen-4.5 | High user preference for granular camera control and multi-motion brushes | Paid Subscription |
| 6 | Hunyuan Video | The highest-ranking open-source model; incredible temporal consistency | Free (Open Source) |
| 7 | Luma Dream Machine (Ray) | Favored for fast generations and dramatic 3D camera fly-throughs | Freemium |
| 8 | Vidu 2.0 (Shengshu) | High Elo for multi-shot narrative coherence and anime stylization | Freemium |
| 9 | Mochi 1 (Genmo) | Top-tier open-weights model excelling at hyper-smooth 60fps motion | Free (Open-weights) |
| 10 | Pika 2.5 | Preferred for short, highly dynamic social media visual effects | Freemium |
Deep Dive: The LMSYS Video Arena Leaders
1. Sora 2 (OpenAI)
OpenAI’s Sora 2 continues to hold the peak Elo rating on the LMSYS Video Arena. Voters consistently select it over competitors when the prompt requires complex object permanence—such as a character walking behind an obstacle and re-emerging identically intact. Its latent architecture acts as a world physics engine, meaning gravity, light reflections, and rigid body collisions behave flawlessly without the dreaded "AI melt" effect.
2. Google Veo 3.1
Google Veo 3.1 frequently trades the #1 spot with Sora depending on the category. It scores exceptionally high on LMArena for exact prompt adherence, meaning it respects highly detailed directorial commands regarding framing and color grading. Its most significant advantage is native audio generation; the model simultaneously generates perfectly synced Foley effects and ambient noise alongside the visual output.
3. Hailuo AI (MiniMax)
Hailuo AI is responsible for one of the biggest upsets on the 2026 leaderboards. In blind A/B testing, the community consistently voted for Hailuo over established Western APIs, particularly in prompts involving fluid dynamics, complex human facial expressions, and rapid scene generation.
4. Kling V3 (Kuaishou)
Kling V3 is a dominant force on LMArena, heavily favored by users aiming for high-end cinematic aesthetics. It excels at rendering photorealistic skin textures, accurate depth-of-field, and extended generation lengths (up to 2 minutes) without losing the structural integrity of the scene.
5. Runway Gen-4.5
While Runway is often judged on its image-to-video capabilities, its pure text-to-video Gen-4.5 model holds a strong Elo rating. Voters prefer Runway when prompts require specific camera maneuvers, such as slow dolly zooms or complex pans, as its training data heavily emphasizes traditional cinematography techniques.
6. Hunyuan Video
Tencent's Hunyuan Video is a historic release, currently sitting as the highest-ranked open-source text-to-video model on the LMSYS leaderboard. By releasing the weights openly, they have allowed developers to achieve proprietary-level temporal consistency and fluid motion locally, completely disrupting the enterprise API market.
7. Luma Dream Machine (Ray)
Luma’s Ray architecture maintains a solid top-10 position thanks to its incredible speed. LMArena users favor it for rapid brainstorming, as it quickly generates physically accurate 3D environments, allowing creators to rapidly iterate on storyboards before committing to longer rendering times.
8. Vidu 2.0 (Shengshu)
Vidu 2.0 scores high marks in human preference for its stylized outputs, including 3D animation and anime-style generations. It is particularly noted for its multi-shot coherence, seamlessly cutting between different angles of the same AI-generated subject while maintaining visual continuity.
9. Mochi 1 (Genmo)
Another massive win for the open-source community, Mochi 1 ranks highly on the leaderboard due to its hyper-smooth, 60 frames-per-second motion capabilities. Built entirely on an open-weights architecture, it is favored by local developers who require smooth, non-jittery physics without paying premium cloud costs.
10. Pika 2.5
Pika remains highly relevant in the fast-paced social media landscape. LMArena voters prefer it for generating dynamic, high-energy clips with stylized visual effects—like explosive text reveals or morphing objects—making it the go-to choice for short-form video marketers.
Perfecting Your Prompts
If you are struggling to write the highly detailed, physical prompts required to trigger these advanced video engines, we highly recommend drafting your scripts and scene descriptions using the best AI for text and reasoning first.
Conclusion
The era of glitchy, unusable AI video is completely behind us. By leveraging the best AI for text to video in 2026—as proven by the rigorous blind testing on the LMSYS Video Arena—creators can manifest physically accurate, cinematic scenes using nothing but text. The barrier to high-end video production has officially disappeared.
Scale Securely with Proven Tools.
Try Blackbox AI

About Sanjay Saini
Sanjay Saini is an Enterprise AI Strategy Director specializing in digital transformation and AI ROI models. He covers high-stakes news at the intersection of leadership and sovereign AI infrastructure. Connect with Sanjay on LinkedIn.
Frequently Asked Questions (FAQ)
According to the LMSYS Video Arena, Sora 2 currently holds the highest Elo score for overall human preference. However, Google Veo 3.1 dominates specific categories like native audio synchronization and prompt adherence.
It is an incredibly close race on the LMArena leaderboards. Sora 2 wins out in blind tests for physical plausibility and long-form object permanence, while Veo 3.1 consistently wins in visual aesthetics and native sound generation.
Yes. Models like Google Veo 3.1 natively process and generate both video and audio simultaneously, outputting cinematic clips with perfectly synced Foley effects, ambient noise, and even dialogue.
On the LMSYS leaderboard, open-weights models like Hunyuan Video and Mochi 1 have caused massive upsets, consistently matching or beating proprietary APIs in fluid dynamics and temporal consistency.
While older models struggled to pass the 4-second mark, the leading 2026 models on LMArena are evaluated on their ability to generate consistent, highly detailed scenes lasting 10 to 60 seconds natively.
Sources & References
- LMArena (LMSYS) Video Leaderboard - The definitive crowdsourced benchmark for comparing text-to-video AI models via blind A/B testing.
- Stanford HAI Artificial Intelligence Index Report - Tracking the rapid global advancement of temporal consistency and physics engines in generative video.
- Best AI Models 2026 (Pillar Guide)
- Best AI for Image to Video 2026
- Best AI for Text and Reasoning
External Sources:
Internal Guides: