5 Dead Giveaways That Reveal "DeepSeek" Writing Instantly (No Tool Needed)

Key Takeaways: The DeepSeek "Fingerprints"
- The "Meta-Commentary" Trap: It announces what it is about to do before doing it.
- The Logic Overkill: Simple questions get complex, multi-step "Chain of Thought" answers.
- The "Both Sides" Safety Net: An extreme refusal to take a definitive stance without a counter-argument.
- Structural Rigidity: An obsession with numbered lists and bolded headers, even in casual writing.
- The "Thinking" Residue: Phrases like "Upon further analysis" or "Let's break this down" often leak from its reasoning layer.
DeepSeek R1 and V3 have changed the game.
Unlike older models that just predict the next word, DeepSeek "thinks" before it writes.
This makes it incredibly smart, but it also leaves a unique trail of evidence.
Software is struggling to keep up. In our massive DeepSeek vs. AI detector stress test, we found that many standard tools fail to flag DeepSeek content entirely.
When the software fails, you have to rely on manual forensics.
Here are the 5 dead giveaways that scream "DeepSeek" to the trained eye.
1. The "Meta-Commentary" Artifacts
The biggest tell of DeepSeek R1 is its tendency to narrate its own process.
Because the model uses a "Chain of Thought" (CoT) process to reason through problems, this internal monologue often bleeds into the final output.
What to look for:
- Sentences that announce the structure: "In this essay, I will first analyze X, and then discuss Y."
- Unnecessary transitional padding: "Having established the first point, we must now consider..."
- Self-referential phrasing: "It is worth noting that..." or "Crucially, we see that..."
Humans rarely announce what they are writing; they just write it.
DeepSeek feels the need to guide you through its logic map.
2. The "Logic Overkill" (Chain of Thought Leakage)
DeepSeek is built for reasoning.
If you ask a simple question, it often provides a complex, multi-layered answer.
For example, if you ask for a quick email draft, DeepSeek might provide a draft plus a rationale for why it chose a certain tone.
The Red Flag:
- Does the complexity match the request?
- If a student is asked for a personal opinion, does the essay break it down into "Economic," "Social," and "Political" factors automatically?
That is the Chain of Thought architecture showing off. It’s too organized to be natural human spontaneity.
3. The "Both Sides" Safety Net
DeepSeek is aggressively fine-tuned to be safe and neutral.
While humans often have biases or strong opinions, DeepSeek struggles to write a sentence that is purely one-sided without immediately hedging it.
The Pattern:
- The "However" Addiction: Look for paragraphs that start strong but immediately undercut themselves with "However, it is important to recognize..."
- The Safety Conclusion: Endings that summarize that "Ultimately, a balance between X and Y is key."
If the writing feels like it is terrified of offending anyone, you are likely reading DeepSeek V3.
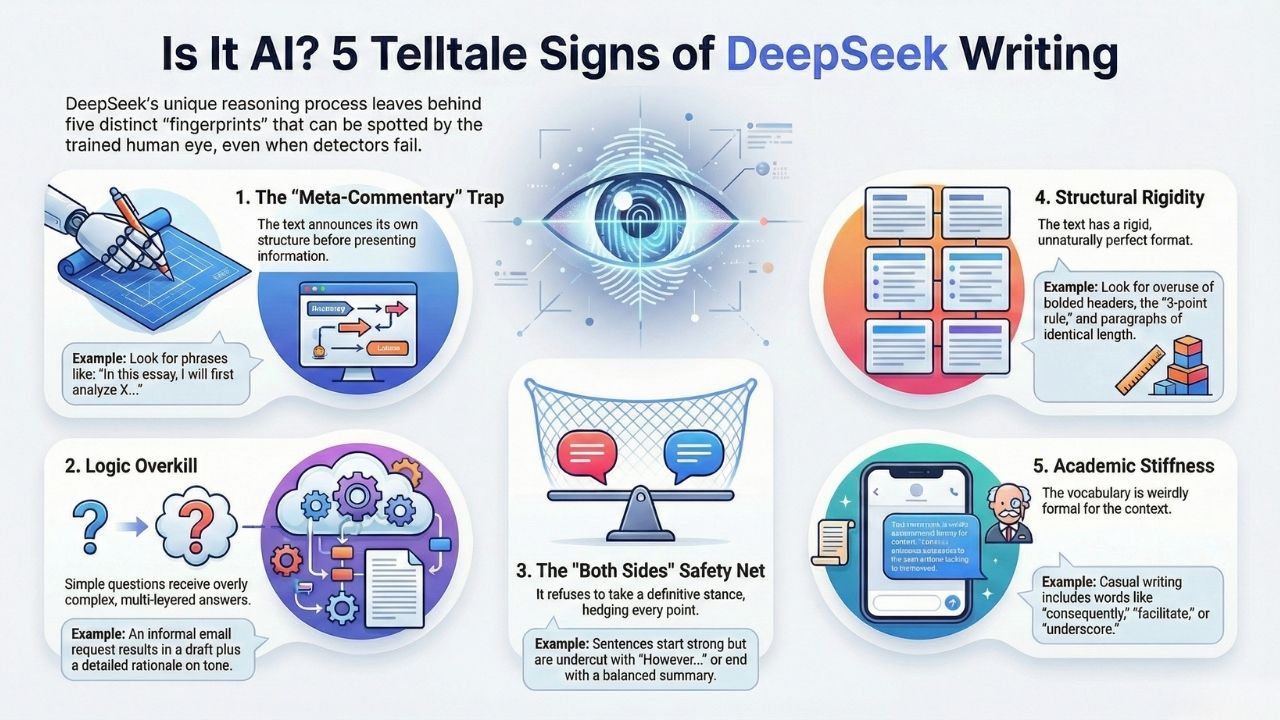
4. Structural Rigidity (The "Perfect" Outline)
DeepSeek loves structure more than any other AI model.
Even when asked for a creative story or a blog post, it defaults to a specific visual format.
Visual Tells:
- Bolded Headers for Every Thought: It hates walls of text. It naturally breaks everything into Bolded Key Points.
- The 3-Point Rule: It frequently provides exactly three reasons, three examples, or three conclusions.
- Symmetry: Paragraph lengths are often suspiciously identical.
Humans write with a rhythm, short sentences followed by long, flowing thoughts. DeepSeek writes in blocks.
When "Humanizers" Hide the Truth
Can these structures be hidden? Yes.
Students are increasingly using "humanizer" tools to scrub these rigid patterns.
We tested this exact scenario in our DeepSeek + StealthWriter test.
You will see that while humanizers can break the structure, they often introduce new grammatical errors that are a "tell" in themselves.
5. The "Academic Stiffness" (Vocabulary Shifts)
ChatGPT has "delve." DeepSeek has its own favorite vocabulary.
Because it is trained heavily on academic and technical data (especially the R1 coding/math model), its casual writing sounds weirdly formal.
The "DeepSeek" Dictionary:
- "Consequently"
- "Facilitate"
- "Underscore"
- "Imperative"
The Test: Read the text out loud.
Does it sound like a conversation, or does it sound like a textbook?
If a 10th-grade student uses the word "underscore" three times in one page, they didn't write it.
Conclusion
Software detectors are useful, but they are not foolproof.
DeepSeek R1 is a powerful engine, but it leaves fingerprints.
It is too structured, too neutral, and too eager to explain its own logic.
By looking for the "Meta-Commentary" and the "Logic Overkill," you can often spot AI writing even when the technology says it's "Human."
Trust your gut. If it reads like a textbook instead of a person, it probably is.
Frequently Asked Questions (FAQ)
Yes. DeepSeek's "Reasoning" models (R1) produce logical flows that mimic high-level human critical thinking better than GPT-4.
However, they are too logical, which is their weakness.
It can, but it usually slips up on the length. DeepSeek tends to over-write.
If you ask for 200 words, it will likely give you 400 words of high-quality analysis.
Partial yes. While tools like StealthWriter remove the "Structural Rigidity" (Tell #4), they rarely fix the "Both Sides" logic (Tell #3).
The underlying argument often remains too neutral to be human.