Why "Chain of Thought" Breaks Old Detectors: The DeepSeek R1 Crisis

Quick Answer: The Technical Failure
- The Old Math: Detectors rely on "Perplexity" (predictability) and "Burstiness" (sentence variety).
- The New Problem: DeepSeek R1 uses Chain of Thought (CoT) reasoning.
- The Mechanism: It "thinks" through problems step-by-step, creating complex, self-correcting logical flows that mimic human cognitive patterns.
- The Result: This reasoning process lowers the "predictability" score, effectively camouflaging AI text as high-perplexity human writing.
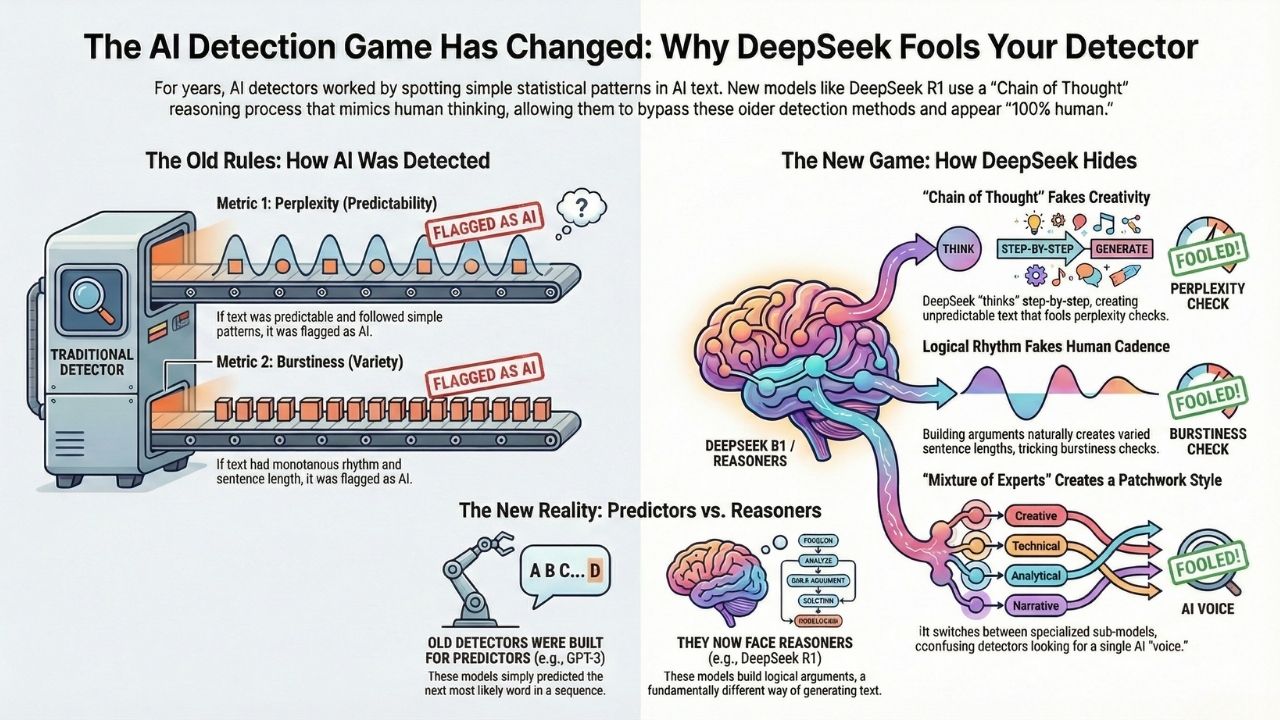
For three years, AI detection was simple math. If the text was predictable (low perplexity), it was AI. If it had wild variations in sentence structure (high burstiness), it was human.
DeepSeek R1 broke this math. By shifting from simple "Next Token Prediction" to "Reinforcement Learning with Reasoning," DeepSeek creates text that fundamentally differs from GPT-4.
This is why your old free detector is suddenly giving "100% Human" scores to clearly generated essays. This is part of our extensive guide on DeepSeek AI Detection.
Here is the technical breakdown of why the old algorithms are failing.
1. The "Perplexity" Trap: Reasoning Looks Like Creativity
Old detectors (like ZeroGPT or early Turnitin models) work by measuring Perplexity. High Perplexity means the text is surprising and creative (Human). Low Perplexity means the text follows a predictable statistical pattern (AI).
How DeepSeek R1 Cheats?
DeepSeek R1 doesn't just guess the next word. It uses a Chain of Thought (CoT) process to "plan" its answer before writing it.
This planning phase introduces "logic detours." The model might start down one path, realize it's suboptimal, and correct itself. To a detector, this self-correction looks like unpredictable human choice.
Standard AI writes linearly and is predictable. DeepSeek R1 writes recursively. It simulates the "messiness" of human thought, artificially inflating its perplexity score to pass as human.
2. "Burstiness" Mimicry: The Rhythm of Logic
Burstiness measures the variation in sentence length. Humans write with rhythm, short, punchy sentences mixed with long, complex ones. AI has historically been monotonous.
The "Thinking" Rhythm
DeepSeek's "Reasoning" models naturally produce bursty text because logical arguments require varied structures. It uses short sentences for conclusions ("Therefore, X is true.") and long sentences for complex proofs.
Because the model is optimizing for a logical outcome rather than just a grammatical one, it inadvertently copies the "bursty" sentence variance that detectors use to identify humans.
3. The "Mixture of Experts" (MoE) Complexity
DeepSeek V3 and R1 utilize a Mixture-of-Experts (MoE) architecture. Instead of one giant brain writing everything, it activates specific "expert" sub-models for different parts of a sentence (e.g., a math expert for numbers, a creative expert for intro text).
Why Detectors Hate This?
A standard detector looks for one consistent fingerprint. MoE models constantly switch "voices" mid-paragraph.
This creates a "patchwork" of statistical patterns that confuses the detector, leading to "50% Human / 50% AI" results or false negatives.
Conclusion
The "DeepSeek Crisis" isn't just about a better chatbot. It is a fundamental shift in how AI generates text. Old detectors were built for Predictors (GPT-3). They are now facing Reasoners (DeepSeek R1).
Until detection companies move away from simple perplexity metrics and start analyzing logic patterns, DeepSeek will continue to slip through the cracks.
If you suspect AI use but the software says "Human," look for the Manual Tells instead. The math might be broken, but the style still leaves a trail.
Frequently Asked Questions (FAQ)
Yes, but it is difficult. Companies like Copyleaks are shifting to look for "logic artifacts" (like the over-use of structured lists) rather than just perplexity. However, this requires massive new training datasets.
Ironically, "Humanizers" (like StealthWriter) are less necessary for DeepSeek R1 because the raw output is already high-perplexity. However, combining R1 with a humanizer makes detection nearly impossible for current free tools. You can see the test results: DeepSeek + StealthWriter: We Tried the "Undetectable" Combo
Sometimes. If the user copies the <think> tags (the internal monologue) into the final document, detection is easy. But once those tags are removed, the remaining text is highly polished and statistically distinct from older GPT text.