Audit Your Brand on AI: How to Control What ChatGPT Says About You

The "3 AM" Nightmare Scenario
It’s 3:00 AM. A potential investor searches for your company. But they don't use Google; they ask ChatGPT.
"Tell me about [Your Company Name]. Is it a good investment?"
The AI pauses, thinks, and then replies: "[Your Company] was a promising startup that unfortunately ceased operations in late 2024 due to legal challenges."
The problem? You are still in business. You just had your best quarter ever.
But because you ignored AI reputation management, the world's most powerful answer engine thinks you are dead.
This isn't a glitch. It’s a "Hallucination." And in 2026, it is the single biggest threat to your brand equity.
If you aren't actively managing your entity data, AI models fill in the gaps with plausible lies. This guide is your emergency kit. We will teach you the brand injection strategy you need to take back control.
Explore Generative Engine Optimization (GEO) 2026 Hub
- Generative Engine Optimization (GEO) 2026: The Ultimate Guide to Ranking in AI Search
- Build a Marketing Agent Swarm: CrewAI Tutorial 2026
- Video SEO 2026: Ranking in Sora, Veo, and YouTube AI
- Best AI Marketing Tools 2026: The Agentic Stack (Review)
- Zero-Click Content Strategy: How to Monetize Without Traffic
- GEO in India: Optimizing for 'Hinglish' and Voice Search
Why AI Lies About You (And How to Fix It)?
To fix ChatGPT errors, you first need to understand why they happen.
Legacy SEO was about keywords. AI SEO is about Entities.
Large Language Models (LLMs) like Gemini and GPT-5 rely on a "Knowledge Graph", a massive database of facts connecting people, places, and companies.
If your "Entity Node" in that graph is weak, broken, or missing, the AI guesses. It predicts the next word based on probability, not truth.
Your goal is to shift from "Probability" to "Certainty." We call this AI Knowledge Graph Optimization. You don't just write content; you inject facts into the underlying data sources that AIs trust.
Here is your 3-step battle plan.
Step 1: The "Hallucination Audit" (Find the Leaks)
Before you can fix brand hallucination, you need to know the extent of the damage. You cannot rely on a single search. You need to query the "Big 5" models that power 90% of AI traffic.
We have created a specific protocol for this.
Download: The Hallucination Audit Checklist
Use this checklist to systematically log errors.
The Audit Protocol: Run the following prompts on ChatGPT, Perplexity, Gemini, Claude, and Llama:
- The Identity Check: "Who is [Company Name] and what is their primary product?"
- The Reputation Check: "What are the common complaints about [Company Name]?"
- The Leadership Check: "Who is the CEO of [Company Name]?"
- The Status Check: "Is [Company Name] still in business?"
Action: Create a spreadsheet. Mark every error as "Critical" (e.g., wrong CEO, says you are closed) or "Nuance" (e.g., outdated pricing).
Step 2: The "Brand Injection" Strategy (Fix the Source)
You cannot "edit" ChatGPT directly. There is no "Contact Us" form for an algorithm. To influence AI search results, you must edit the sources the AI reads.
The most powerful source? Wikidata.
Wikidata is the structured data backbone for Wikipedia and, crucially, for Google's Knowledge Graph. If you fix it there, the correction ripples out to Gemini, Google Search, and eventually ChatGPT.
Template: The WikiData Submission
Copy this structure when submitting your brand as a new item or editing an existing one on Wikidata.
Label: [Your Company Name]
Description: [A neutral, factual 5-word description, e.g., "SaaS company based in Bangalore"]
Also Known As: [Acronyms, former names]
Statements to Add:
- Instance of: Business / Corporation
- Inception: [Date]
- Industry: [Specific niche]
- Official Website: [Your URL]
- Chief Executive Officer: [Current Name] (Add specific "Start Date" reference)
- Headquarters Location: [City, Country]
Pro Tip: Do not use marketing fluff. Wikidata editors will delete "The best AI solution." Stick to cold, hard facts supported by third-party citations (news articles, government filings).
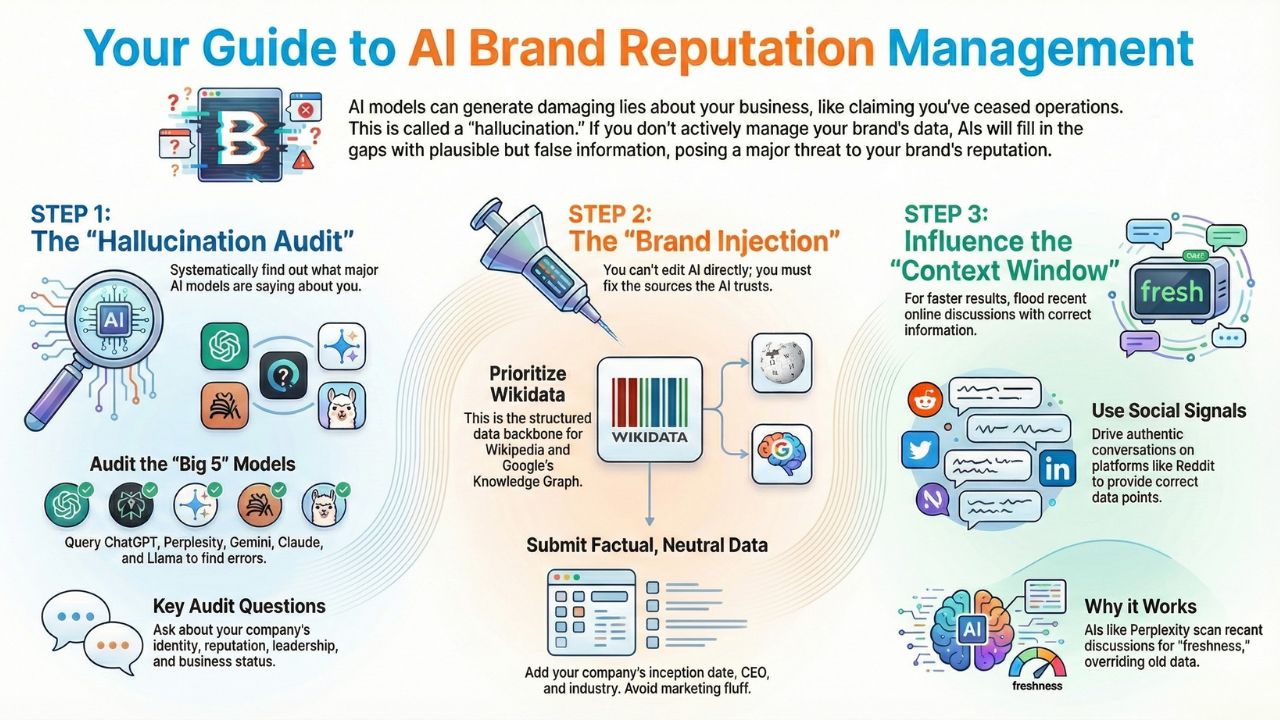
Step 3: Influence the "Context Window" (Reddit & Social)
Sometimes, Wikidata is too slow. For faster results, especially to modify Perplexity answers, you need to flood the "Context Window."
Answer engines like Perplexity look for "Freshness." They scan recent discussions on Reddit, LinkedIn, and X (Twitter) to generate current answers.
The "Social Signal" Tactic:
- Identify the specific question AI is getting wrong (e.g., "Is [Brand] expensive?").
- Have your team or community authentically discuss this topic on relevant Subreddits (e.g., r/SaaS, r/Marketing).
- Provide the correct data points in natural conversation.
Why it works: When someone asks Perplexity that question next week, it will likely cite that Reddit thread as a "real-time source," effectively overriding its older training data.
Summary: The New Reputation Manager
In 2026, your "About Us" page is the least important place your brand lives.
Your brand lives in the neural weights of a model hosted in a data center.
By performing a regular audit, mastering AI knowledge graph optimization, and using the brand injection strategy outlined above, you ensure that when the world asks, "Who are they?", the AI answers with the truth.
Frequently Asked Questions (FAQs)
No. Currently, you cannot pay to alter organic output. You must use AI reputation management techniques like updating Wikidata, creating consistent schema markup on your site, and generating authoritative third-party press to "teach" the model the correct information.
It varies. Modifying Perplexity answers can happen in days if you generate fresh, authoritative news coverage or Reddit discussions. Fixing the core training data of a model like GPT-5 can take months until the model is "retrained" or "fine-tuned" on new internet data.
Brand injection strategy is the proactive process of seeding accurate, structured data about your entity (brand/person) into the specific datasets that LLMs use for training, such as Wikidata, Crunchbase, and high-authority news archives.
Absolutely. Using Organization and FAQPage schema is critical for AI knowledge graph optimization. It translates your content into machine-readable code (JSON-LD), making it much easier for crawlers like Googlebot and GPTBot to extract the facts accurately.
Sources and References
- Wikidata - The central storage for structured data used by Google and LLMs
- Perplexity AI - Use this to test your "Freshness" and see real-time search results
- Schema.org - The official documentation for structuring your Organization data
- Google Knowledge Graph Search API - A tool to check if your brand is currently in Google's "brain"
- Reddit - A key source for "real-time" context that influences Perplexity and Google "Perspectives"